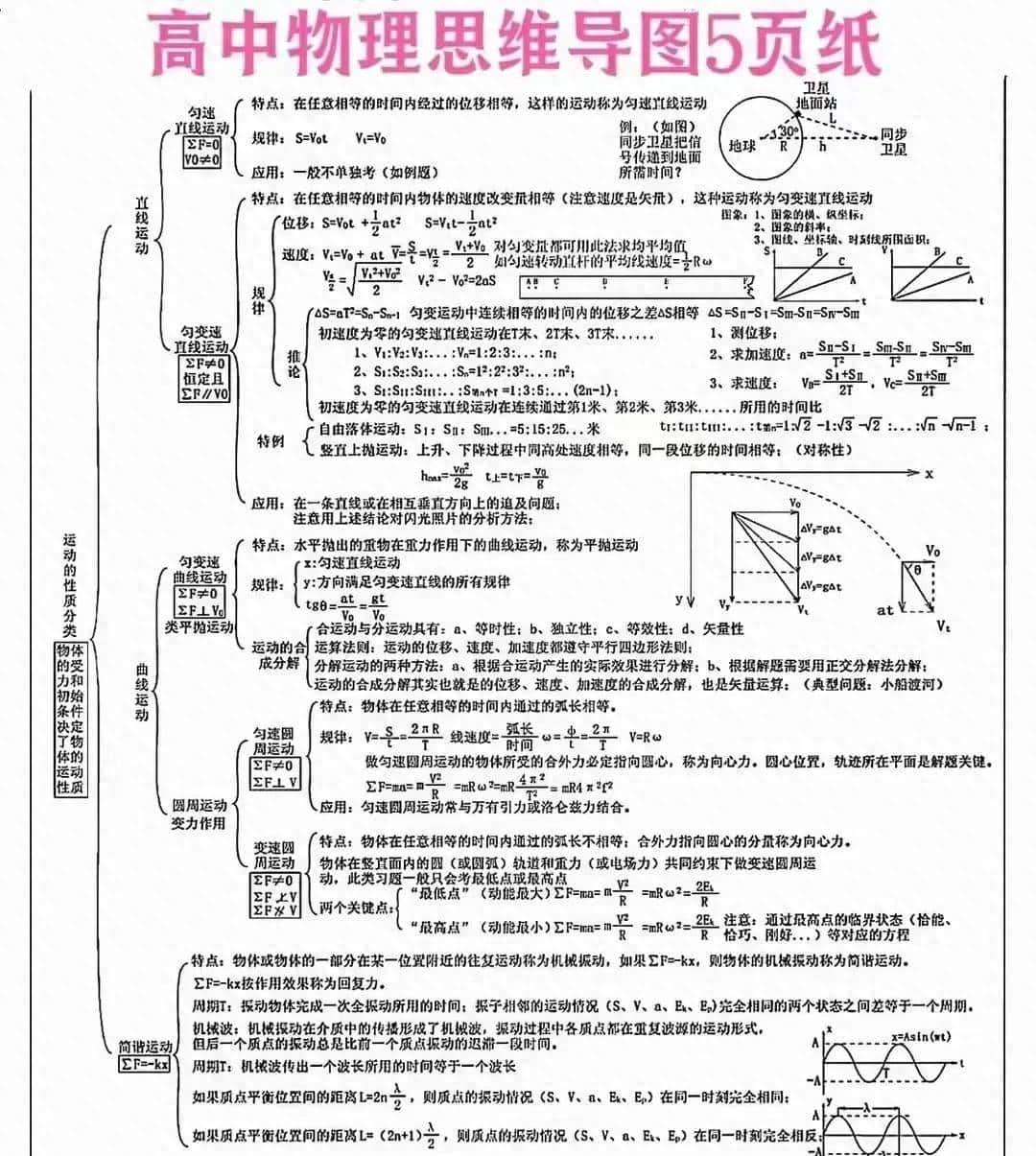
DeepSeekMath‑V2 在多项高难度数学竞赛上交出成绩单:IMO 2025 和 CMO 2024 达到金牌水平,Putnam 2024 拿下 118/120 的接近满分成绩。这个结果公布后,外界对它能不能做到“有证可查”的数学推理开始多看几眼。

接着看它到底是怎么做到的。DeepSeek 团队把重点放在“过程能被验证”这一点上。他们觉得只看最终答案不够,特别是定理证明这类题,关键在于每一步推导的严谨性。为此,团队在模型之外另外搭了一个基于大模型的验证模块,用来审查模型生成的证明链。生成一段证明后,验证器会逐步复核每一步,有不明确或逻辑不足的地方就会指出来,模型据此补充或改写,形成一个循环迭代的训练过程。
训练环节也不是简单喂数据。团队让验证器不仅查错,还去“挖更难的题”。具体做法是让验证器扩展计算,故意提出更苛刻的检验条件和更细化的问题分支,把模型逼到边界上,从这些失败或半成功的案例里生成高难度样本,再把这些样本回喂回来提升验证器和生成器的能力。可以理解为一个“自我出题、自我审题、自我纠错”的闭环。这个闭环被用来不断提升模型在严谨推导上的表现,而不是单纯追求答对多少题。

关于模型的底子,DeepSeekMath‑V2 是建立在 DeepSeek‑V3.2‑Exp‑Base 之上的改善版。官方给出的评测里,不仅列出了竞赛成绩,也提供了模型在不同题型上的表现对比,显示出在需要分步推导的题目上复现率和自检能力显著提升。团队还说明,尽管目前结果看起来不错,但里头的验证器、样本生成策略和训练细节还远没到“万事大吉”的程度,许多工程和理论问题还在推进中。
从时间线说起:这条新闻是 IT之家在11月27日发出的报道。报告里把技术点、训练方法和竞赛成绩都列出来了,并给出了模型和代码的公开地址——Hugging Face 和 Github 都有相应页面,方便研究者去看具体实现与样例。官方在公开说明里强调,这条“可自验证数学推理”的研究路线是可行的,是后续构建更可靠数学智能系统的一条可能路径,但不是最终答案。
再回到具体流程,实际运行时会有几个环节交替出现。模型先给出一版证明草稿,验证器跑一遍逻辑链和必要的计算,若发现不完整的推导或潜在错误,会把问题点标出来并请求模型细化;模型根据反馈补写子证明或补充中间步骤,验证器再检验。这个过程可能重复多次,直到验证器无法找到明显漏洞,或者超出资源限制为止。为了让验证器更强,团队还让它通过数学计算去生成对抗样本——也就是刻意制造边界情况和易错点,用来训练模型在真正复杂场景下的稳定性。
成绩落在几次大型竞赛上面试金。有细节数据支撑:IMO 2025 和 CMO 2024 给出了“金牌水准”的结论,Putnam 2024 上的 118/120 数字接近满分,说明在高度抽象和创造性要求高的题目上,模型也能交出接近人类顶尖选手的解答。看到这个成绩,有点意外也有点正常——意外在于系统化的自检机制的确 带来了明显效果,正常在于数学题本来就是能被形式化的对象,合适的验证策略天然比较适合这类问题。
技术开放性方面,团队把模型和代码放到公开平台,便于同行复现和检查。地址在 Hugging Face 和 Github,都能看到模型权重和部分训练细节。给出链接方便查阅:Hugging Face:
https://huggingface.co/deepseek-ai/DeepSeek-Math-V2;Github:
https://github.com/deepseek-ai/DeepSeek-Math-V2。
在实践中,验证器的设计和训练依旧是关键瓶颈。要让验证器既能自动发现逻辑漏洞,又不会把正常但省略步骤的好证明误判为错误,这需要精细的策略和大量例子。团队目前的办法是通过扩展计算和对抗样本缓解这一矛盾,但这只是其中一部分。资料里还提到,未来方向包括提升验证器的推理细粒度、减少人工干预,以及把这种自验证机制推广到更多数学分支上去。
报道里没有给出全部细节,许多实现层面的参数和工程技巧需要读者自己去仓库里看。总体上可以看出一个思路:把“能不能被验证”放在前面,用自动审查和对抗样本的循环来强化模型,而不是单纯追求正确率指标。工作还在进行中,代码和模型可在上面两个地址找到,方便感兴趣的人进一步复现或借鉴。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...