
前言:你以为懂了,实则差得远
说实话,许多人聊到PFC就是”无损网络”、”优先级流控”这些概念,听起来挺专业,但一到实际场景就傻眼。为啥?由于PFC这东西远不是开个开关那么简单。今天咱们就把这些机制掰开揉碎了说清楚——不是教科书那套,而是你真正在网络里会遇到的坑和解决办法。
PFC的本质:一个”逼不得已”的妥协方案
先说个许多人不愿承认的实际:PFC从设计上就是个妥协产物。
传统以太网压根不保证数据包能到达目的地,丢包了?上层协议(列如TCP)自己重传去。这套路对普通应用还行,但到了数据中心,特别是存储网络(FCoE)和高性能计算(RDMA),丢包就是灾难。
于是IEEE 802.1Qbb标准搞出了PFC——在链路层加个”刹车系统”。关键点在于:它不是给整条链路踩刹车(那是802.3x的老古董做法),而是可以按优先级精细控制。你想想看,就像高速公路上,出事故了不是封整条路,而是只封一两个车道,其他车道照跑。
机制拆解:不只是Pause Frame那么简单
1. 基础流控机制
PFC的核心就是在接收端buffer快满的时候,发PAUSE帧给上游设备,让它别再发特定优先级的流量了。听起来简单,但魔鬼在细节:
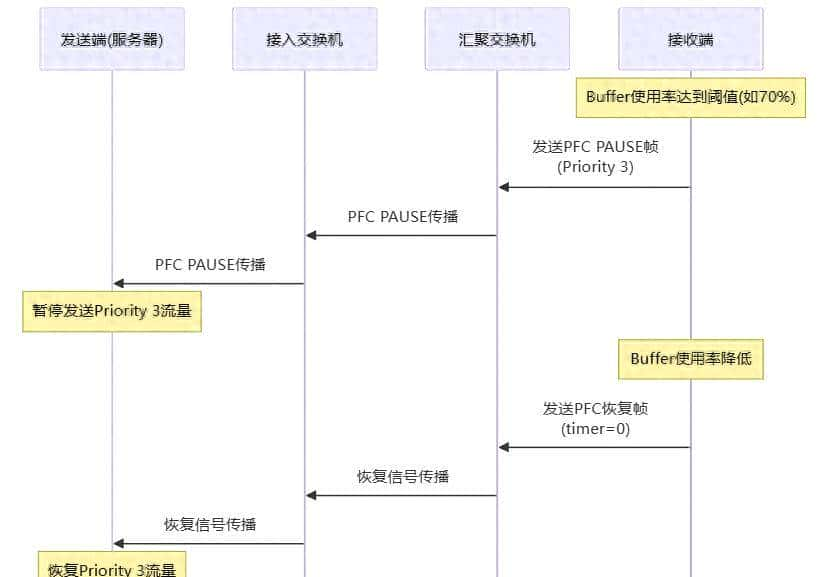
这里第一个坑:PAUSE帧是逐跳传播的,不是端到端的。这意味着什么?意味着一个边缘节点的拥塞,能一路传导到整个网络。就像多米诺骨牌,一个倒了,全倒。这就是所谓的”PFC风暴”。
2. PFC Watchdog:救命稻草还是饮鸩止渴?
既然PFC会传播拥塞,那怎么办?业界的答案是PFC Watchdog(看门狗机制)。
这东西的原理说白了就是:设个定时器,如果某个队列被PAUSE的时间超过阈值,强制恢复发送。
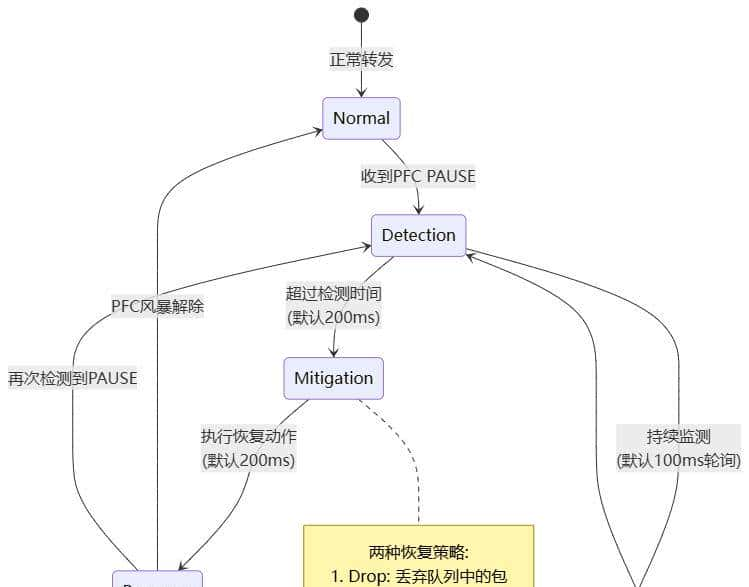
这里有个许多人不知道的细节:Watchdog的三个关键参数——轮询间隔(polling interval)、检测周期(detection period)和恢复时间(recovery time)——直接决定了你的网络能不能活。
举个实际例子:某AI训练集群,GPU之间跑RDMA,网络工程师把detection period设成了500ms(想着保守点)。结果呢?每次集群突发流量,PFC storm触发,但Watchdog反应太慢,应用层已经超时重传了,网络性能直接腰斩。后来把detection period调到100ms,recovery time调到200ms,问题才解决。
3. Remote PFC (rPFC):别让整个网络陪葬
华为在自家设备上搞了个rPFC,思路实则很机智:别让PAUSE帧满网络乱窜,直接告知源头”老兄,你慢点”。
传统PFC的问题是什么?拥塞发生在网络边缘(列如某台服务器的接收buffer满了),PAUSE帧一路传播,spine交换机、leaf交换机全受影响。rPFC的做法是:
- 在目的交换机检测到拥塞时,不发PAUSE帧
- 而是发个特殊的rPFC通知包,直接路由到源交换机
- 源交换机收到通知,对源服务器执行PFC

评价:这个方案理论上很美好,但有个前提——你的网络得全是支持rPFC的设备。现实情况是,大多数数据中心都是多厂商混合组网,rPFC就成了”纸上谈兵”。
4. DCBX:自动配置的双刃剑
Data Center Bridging Exchange (DCBX) 是基于LLDP的自动配置协议。它能让交换机和服务器自动协商PFC参数,听起来很方便对吧?
但我要说的是:生产环境别指望它。
为什么?由于DCBX的”自动协商”逻辑常常和你想要的不一样。举个例子:
- 你的交换机配置了Priority 3和4做PFC
- 服务器网卡默认只支持Priority 3
- DCBX协商结果:Priority 4的PFC被禁用
结果就是,原本规划好的无损网络,Priority 4的流量开始丢包,应用直接挂掉。
提议做法:
- 生产环境手动配置PFC,别信自动协商
- 用DCBX仅作为监控和告警工具,检测配置不一致
- 交换机端设置”willing=0″(不接受peer配置)
5. ECN + PFC:真正的无损网络
如果只用PFC,你迟早会遇到”头阻塞”(Head-of-Line Blocking)问题。什么意思?就是一个队列被PAUSE了,导致其他本该正常转发的流量也被卡住。
解决方案是ECN (Explicit Congestion Notification),这才是现代数据中心的标配组合。
ECN的原理:
- 交换机在队列深度达到某个阈值(列如55%)时,不发PAUSE帧
- 而是在IP包头打个CE标记(Congestion Experienced)
- 接收端看到CE标记,发CNP包(Congestion Notification Packet)给发送端
- 发送端主动降低发送速率
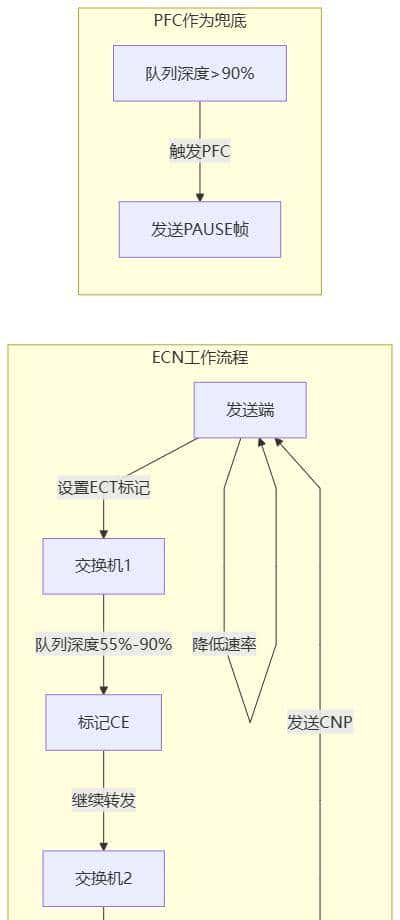
这里的关键参数:
- ECN阈值一般设在55%-90%队列深度
- PFC阈值设在95%以上
- 这样ECN先起作用,PFC只在极端情况下触发
实战数据:某个RDMA存储集群,只用PFC时,尾延迟(P99)达到2ms;加上ECN后,P99降到200us,直接10倍提升。
配置指南:别再复制粘贴了
场景一:RDMA存储网络
这是最常见也最容易翻车的场景。你需要:
1.确定无损优先级
一般用Priority 3做RDMA流量
Priority 0-2留给常规流量(lossy)2.配置Queue到Priority的映射
# 示例配置(Cisco NX-OS风格)
class-map type qos match-all RDMA
match dscp 26 # RoCEv2常用DSCP值
policy-map type qos RDMA-POLICY
class RDMA
set qos-group 3 # 映射到Priority 3
system qos
service-policy type qos input RDMA-POLICY3.启用PFC + ECN
# 接口配置
interface Ethernet1/1
priority-flow-control mode on
priority-flow-control priority 3 no-drop
# ECN配置
qos random-detect dscp-based
qos random-detect ecn threshold 55 904.配置PFC Watchdog
# 关键参数
system qos
pfc-watchdog
detection-time 200
restoration-time 200
restore-action forward # 不丢包,忽略PAUSE继续发踩坑提示:许多人只配了交换机端PFC,服务器网卡忘了配,结果单向PFC,照样丢包。记住:PFC是双向的,两端都要配!
场景二:AI/ML训练集群
AI训练对网络延迟极其敏感,这里有几个特殊思考:
1.多条无损队列
Priority 3: GPU-to-GPU allreduce流量
Priority 4: 存储访问(checkpoint)
Priority 5: CNP包(ECN的反馈包)2.更激进的ECN阈值
# AI集群提议用更低的ECN阈值
qos random-detect ecn threshold 30 60
为啥?由于AI训练的incast流量特别严重,等队列深度到55%再反应,已经晚了。3.Asymmetric PFC
接收端:处理所有优先级的PAUSE
发送端:只为配置的无损优先级发PAUSE
这样可以避免意外的PFC传播。场景三:混合流量数据中心
这种场景最复杂,由于你得在无损(FCoE/RDMA)和有损(常规IP流量)之间取得平衡。
关键策略:
1.Buffer分区
# 入向buffer分配
ingress buffer lossless: 80%
ingress buffer lossless-headroom: 10% # 给PAUSE传播的时间
ingress buffer lossy: 10%
# 出向buffer分配
egress buffer lossless: 80%
egress buffer lossy: 10%
egress buffer multicast: 10%2.带宽保证(ETS)
# 即使有损流量突发,也保证无损流量最低带宽
scheduler RDMA
bandwidth percent 60
scheduler Normal
bandwidth percent 30
scheduler CNP
bandwidth percent 5
priority strict-high # CNP要最高优先级!实战案例:某云厂商的混合集群,开始把80%带宽给了常规流量,20%给RDMA。结果AI训练任务动不动就timeout。后来反过来,RDMA拿60%,常规流量拿30%,问题解决。教训:别低估无损流量的带宽需求。
你必须知道的几个真相
真相1:PFC不等于零丢包
许多人以为开了PFC就”无损网络”了,错!
PFC只保证拥塞时不丢包,但其他情况(列如硬件故障、配置错误、cable问题)该丢还是丢。我见过一个案例,网线不达标(Cat5e跑10G),物理层就有bit error,PFC也救不了。
真相2:PFC Watchdog会丢包
是的,你没看错。Watchdog的restore-action如果设成”drop”,那在recovery期间,队列里的包会被扔掉。如果设成”forward”,虽然不丢包,但忽略PAUSE继续发,下游照样可能溢出。
这是个艰难的选择:
- Drop模式:牺牲一些包,快速恢复网络
- Forward模式:不丢包但可能导致下游拥塞扩散
我的提议:优先用Forward模式,但detection-time要设短(100-200ms),别让PFC storm持续太久。
真相3:DCBX在异构网络基本没用
Cisco、Arista、Mellanox各家的DCBX实现都有差异,想靠自动协商配置整个网络?做梦。
我见过的最佳实践:手动配置 + DCBX监控。让DCBX跑起来,但只用来检测和告警配置不一致,别让它真的去改配置。
真相4:优先级规划比技术参数更重大
这是最容易被忽视的。你可以把PFC的所有参数调到完美,但如果优先级规划错了,照样翻车。
常见错误:
- 把所有重大流量都塞到Priority 3
- 忘了给CNP包单独的高优先级队列
- 没思考到不同应用的流量特征(突发 vs 稳定)
正确做法:
- 列出所有流量类型和它们的特征
- 根据延迟敏感度和丢包容忍度分优先级
- 无损流量(FCoE/RDMA)用3-5
- CNP用最高优先级(7)或单独队列
- 管理流量(BGP/LLDP)也要保护
总结:PFC是门艺术,不是科学
说到底,PFC不是个”开关”,而是个需要精心调优的系统。你得理解:
- PFC是最后一道防线,不是第一选择。先优化应用、调整拓扑,实在不行才上PFC。
- ECN + PFC才是王道。单用PFC,你早晚会遇到PFC storm;单用ECN,极端情况还是丢包。两个一起用,互补。
- Watchdog参数没有银弹。不同场景(存储、AI、混合流量)需要不同的参数。照抄别人的配置,八成要踩坑。
- 异构网络手动配置。别指望DCBX,手动配清楚,写好文档,定期review。
- 监控和可观测性至关重大。你得实时看到:
哪些端口在发PAUSE
Watchdog触发了多少次
ECN标记的包有多少
应用层的尾延迟(P99/P999)最后送你一句话:如果你的网络需要PFC,先反思是不是设计有问题。PFC解决的是”拥塞”,但更好的做法是别让拥塞发生——更多带宽、更好的负载均衡、应用层流控,这些才是根本。
PFC,用好了是救命稻草,用不好就是灾难放大器。希望这篇文章能让你少踩坑,网络更稳。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...