
Deepseek 的火爆出圈,将众人的注意力牵引至 AI 大模型之上。不过,紧接着大家又对诸如量化、蒸馏以及剪枝等名词感到迷茫。那么,本文将深入浅出地阐释这三者的概念与关系。

量化、蒸馏与剪枝乃是深度学习里三项关键的模型优化技术,分别自不同的视角化解模型效率和性能的平衡难题。以下为三者的详尽解析:
1. 量化(Quantization)
一句话总结:把模型中的“小数点位数”减少,用更粗糙但更高效的方式表明数字。
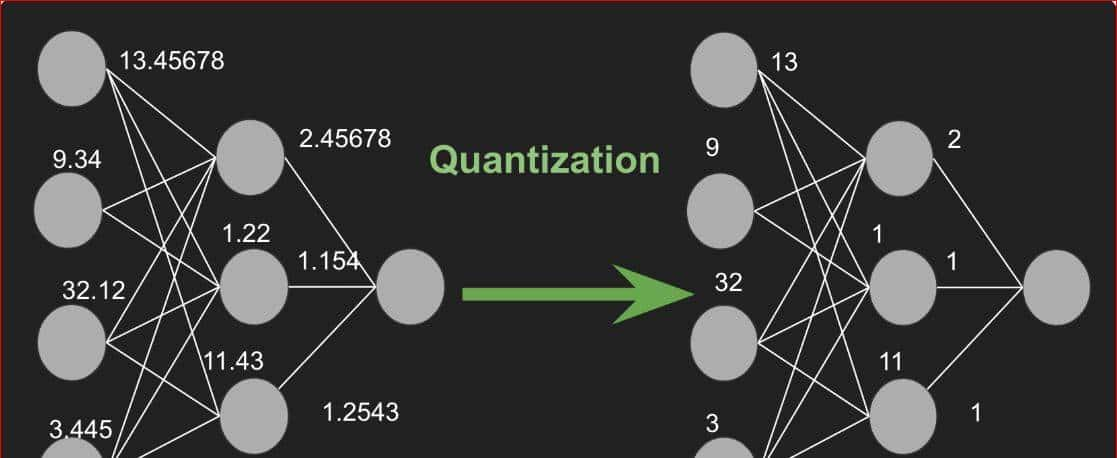
原理:
- 假设原本模型用 32 位浮点数(例如 3.1415926),量化后会变成8位整数(例如3或3.14)。
- 就像拍照时用高清模式(文件大但细节多)和普通模式(文件小但略模糊),量化是模型的“压缩模式”。
具体方法:
- 训练后量化(Post-training Quantization):
模型训练完成后,直接转换数值精度。简单快速,但精度可能下降。
例如:把训练好的 ResNet 模型从 FP32 转为 INT8。 - 量化感知训练(Quantization-aware Training):
在训练过程中模拟量化效果,让模型提前适应低精度。精度损失更小。
例如:训练时加入“伪量化”操作,让权重和激活值适应整数计算。
实际效果:
- 内存节省:32位 → 8位,模型体积减少 4 倍。
- 计算加速:整数运算比浮点运算快,尤其在手机芯片或边缘设备(如树莓派)上。
- 硬件友善:许多 AI 加速芯片(如TPU、NPU)直接支持 8 位计算。
举个实际例子:
- 原始模型:ResNet-50(FP32),大小 98 MB,推理速度 50 ms/张图。
- 量化后模型:ResNet-50(INT8),大小 25 MB,速度 20 ms/张图,精度下降 1%~2%。
缺点和挑战:
- 精度损失:某些对数值敏感的任务(如目标检测)可能受影响较大。
- 兼容性问题:部分模型层(如自定义操作)可能不支持量化。
- 解决方法:混合量化(部分层保留高精度)或量化感知训练。
示例代码:
import torch
from torch.quantization import QuantStub, DeQuantStub
class QuantizedModel(torch.nn.Module):
def __init__(self):
super(QuantizedModel, self).__init__()
self.quant = QuantStub() # 量化入口
self.dequant = DeQuantStub() # 量化出口
def forward(self, x):
x = self.quant(x) # 对输入进行量化
# 假设有一个卷积层
x = torch.nn.Conv2d(3, 64, kernel_size=3)(x)
x = self.dequant(x) # 将结果去量化以便后续处理
return x
# 初始化模型和量化配置
model = QuantizedModel()
model.qconfig = torch.quantization.get_default_qconfig('fbgemm') # 使用默认的量化配置
torch.quantization.prepare(model, inplace=True)2. 蒸馏(Knowledge Distillation)
一句话总结:让“小学生”模型模仿“教授”模型,学其精华,去其糟粕。
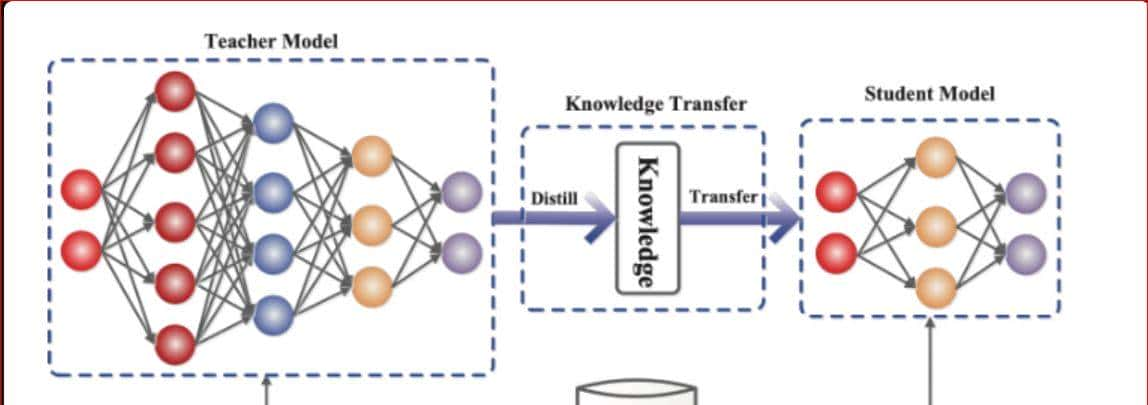
原理:
- 老师模型(Teacher):复杂、高性能的大模型(例如 GPT-3)。
- 学生模型(Student):结构简单的小模型(例如 TinyBERT)。
- 学生不仅学习真实标签(如“这张图是猫”),还学习老师输出的“软标签”(如“猫的概率 90%,狗的概率 5%,其他 5%”),后者包含更多知识。
具体方法:
- 软标签(Soft Labels):
老师模型的输出概率(例如分类任务的类别概率)包含更多信息,列如“猫和狗很像”。
例如:老师输出 [猫: 0.9, 狗: 0.1],而真实标签是 [猫: 1.0, 狗: 0.0]。 - 温度参数(Temperature):
在 Softmax 中引入温度参数,让概率分布更平滑,学生更容易学习到类别间的关系。
例如:高温(T=10)时,老师输出 [猫: 0.7, 狗: 0.3];低温(T=1)时,老师输出 [猫: 0.99, 狗: 0.01]。 - 损失函数:
学生模型的损失 = 真实标签的损失 + 老师输出的损失(模仿老师的判断)。
实际应用:
- BERT → TinyBERT:将BERT的知识蒸馏到更小的模型中,体积缩小7倍,速度提升9倍,性能保留90%以上。
- 语音识别:用大模型教小模型,在手机端实现实时语音转文字。
变体:
- 自蒸馏(Self-Distillation):同一个模型的不同部分相互学习(例如深层教浅层)。
- 离线蒸馏 vs 在线蒸馏:
- 离线:老师模型固定,只训练学生。
- 在线:老师模型和学生模型同步训练。
缺点:
- 学生模型的上限受限于老师模型。
- 训练过程更复杂,需要调参(如温度值、损失权重)。
示例代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class Teacher(nn.Module):
def __init__(self):
super(Teacher, self).__init__()
self.fc = nn.Linear(28*28, 10)
def forward(self, x):
return F.softmax(x / 3.0, dim=1) # 使用温度为3.0进行软化
class Student(nn.Module):
def __init__(self):
super(Student, self).__init__()
self.fc = nn.Linear(28*28, 10)
def forward(self, x):
return F.softmax(x / 1.0, dim=1) # 学生一般使用较低的温度
# 初始化教师和学生模型
teacher = Teacher()
student = Student()
criterion = nn.KLDivLoss() # 使用KL散度损失进行蒸馏
optimizer = torch.optim.Adam(student.parameters(), lr=0.001)
for images, labels in dataloader:
optimizer.zero_grad()
outputs_teacher = teacher(images.view(batch_size, -1))
outputs_student = student(images.view(batch_size, -1))
loss = criterion(outputs_student.log(), outputs_teacher)
loss.backward()
optimizer.step()3. 剪枝(Pruning)
一句话总结:给模型“减肥”,去掉没用的参数,就像整理衣柜丢掉不穿的衣服。
原理:
- 神经网络中有大量冗余参数。剪枝通过评估参数重大性,去掉对结果影响小的参数。
- 结构化剪枝:删除整个神经元、通道或层(适合硬件加速)。
例如:删除卷积层的某些通道。 - 非结构化剪枝:随机删除单个权重(模型更小,但需要特殊硬件支持稀疏计算)。
例如:一个权重矩阵中 50% 的值被置零。
具体步骤:
- 训练原始模型:正常训练一个高性能的大模型。
- 评估重大性:根据权重绝对值、梯度大小或对输出的影响,判断哪些参数重大。
- 剪枝:去掉不重大的参数(例如删除绝对值最小的 50% 权重)。
- 微调(Fine-tune):重新训练剪枝后的模型,恢复性能。
- 迭代剪枝:重复上述过程,逐步压缩模型。
实际例子:
- LeNet-5 剪枝:原始模型 1.7 万参数,剪枝后剩 0.4 万,准确率几乎不变。
- Transformer 剪枝:删除注意力头或隐藏层维度,减少计算量。
高级方法:
- 稀疏训练(Lottery Ticket Hypothesis):
在训练早期识别出重大的子网络(“中奖彩票”),重新训练这个小网络。 - 自动剪枝:用强化学习或遗传算法自动决定剪枝比例和位置。
缺点:
- 非结构化剪枝后的稀疏模型需要专用库(如 TensorFlow Lite)或硬件支持。
- 剪枝过多会导致模型无法恢复性能(“剪秃了”)。
综合应用:三剑客合体
这三种技术常结合使用,例如Google的MobileBERT同时采用蒸馏、量化和结构化剪枝,在自然语言理解任务中达到SOTA效率。未来趋势将更注重自动化压缩(AutoML for Compression)与硬件协同设计。
部署提议:
- 端侧设备优先组合量化+剪枝(如Tiny-YOLO)
- 云服务可叠加蒸馏+量化(如DistilBERT+INT8)
- 高稀疏模型(>90%)提议使用专用推理引擎(如TensorRT)
示例代码:
import torch
from torch.nn.utils import prune
class SimpleModel(torch.nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 64, kernel_size=3)
self.fc = torch.nn.Linear(64*28*28, 10) # 假设输入为28x28的图像
def forward(self, x):
x = self.conv1(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
model = SimpleModel()
# 对全连接层应用L1范数剪枝,剪枝比例为20%
prune.l1_unstructured(model.fc, 'weight', amount=0.2)
# 移除被剪枝的权重
prune.remove(model, 'fc.weight')总结对比
|
技术 |
核心思想 |
优点 |
缺点 |
适用场景 |
|
量化 |
降低数值精度 |
显著减少内存和计算量,硬件友善 |
可能损失精度,部分操作不支持量化 |
移动端、嵌入式设备部署 |
|
蒸馏 |
小模型模仿大模型 |
小模型性能接近大模型,灵活性强 |
依赖大模型,训练复杂 |
需要轻量级模型但要求较高性能的任务 |
|
剪枝 |
删除不重大参数 |
减少计算量,模型更小 |
需要微调,非结构化剪枝硬件支持有限 |
资源受限环境,需减少计算开销 |
希望这些细节能帮你彻底理解!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

您必须登录才能参与评论!
立即登录

收藏了,感谢分享